
Explainable AI:
Our Resolve™ disambiguation engine, and how it works
At Xapien, we prioritise simplicity and transparency. While our reports are created using complex and cutting-edge technology, we strive to present our findings in a clear and easy-to-digest way.
In that spirit, our ongoing blog series aims to explain the workings of our Explainable AI technology in the simplest way possible. By doing so, you’ll have a clear understanding of how and why the information in our reports is presented to you.
Having this knowledge isn’t just valuable for understanding how our reports work. It can also help put your due diligence, compliance, or Know Your Customer processes into context and assist you in explaining these processes to your colleagues, customers, or regulators.
In this article, we’ll focus on Disambiguation, also known as Entity Resolution. Read our previous explainers on Natural Language Processing and the challenge of matching names across languages.
First, what is Explainable AI?
Explainable AI (XAI) is a subdivision of AI that makes the decisions and predictions produced by AI models interpretable and transparent to humans.
The goal of XAI is to create AI systems that can clearly justify how they arrived at a certain decision or prediction, rather than just providing a mysteriously-formed output. It’s like the AI equivalent of ‘showing your working’.
We use XAI because it plays a crucial role in fostering trust in AI systems and making them suitable for tasks like due diligence. But regulatory bodies such as the Financial Conduct Authority and the Solicitors Regulation Authority can also request organisations to provide evidence of the thorough due diligence they’ve conducted on accepted clients using AI.
Where does disambiguation enter?
When humans read multiple articles about an individual, we have a natural instinct to consider different aspects surrounding each mention of that person. It’s how we confirm whether they’re the person we’re interested in or not.
We might consider how other people, sectors, topics or organisations are mentioned in context. We then use this information along with what we already know to form a judgement about how likely the article is to be about our subject.
At Xapien, we call this ‘disambiguation’. It’s how we know which references to entities are coreferent, meaning they refer to the same entity.
The challenges of disambiguation
Disambiguation presents a challenge in multiple areas, like the selection of doctors for clinical trials by medical companies. When examining their professional histories on databases, it becomes evident that a doctor can be referred to by different names. For example, you may come across variations such as ‘Dr. John Smith,’ ‘Doctor Smith,’ ‘J. Smith,’ or ‘John D. Smith.’
This makes it hard to fully understand a particular doctor without carefully looking at each reference separately. Now imagine that you need to manually check each reference on the entire indexed internet to do this. That’s what we do at Xapien.
Likewise, different names don’t always refer to different entities. Nicknames, aliases, and name changes can result in different names referring to the same entity. Sometimes the second element of a double-barreled name is skipped, or a middle name is included. And, names that are translated from a different language can take many forms.
Then there’s the fact you don’t know how many relevant mentions of your entity there are. Before you carry out entity resolution, it’s impossible to know how many distinct entities are associated with a name. For example, there could be thousands of references to ‘John Smith’. Without disambiguation, you wouldn’t know if they refer to a single person, ten people, or a thousand people.
Human disambiguation and pairwise comparison
Human disambiguation relies on our intricate and often instinctive understanding of contextual clues and logical deductions. It’s the process of determining whether two entities are the same or not, and it involves something called ‘pairwise comparison’.
In pairwise comparison, we compare entities in pairs to assess which one is more likely to be the desired one or if the two entities are identical. The challenge is that as the number of references grows, the number of pairs increases, making it a time-consuming task.
To give you an idea, just four references would need us to consider six pairs of people. Now, imagine the complexity when dealing with a small Xapien report that involves at least 30,000 mentions. In such a case, there would be a staggering 500 million pairs to evaluate. Without Xapien’s capabilities, getting quick results would be virtually impossible.
Xapien searches require advanced logic
Name matching is no longer a particularly unusual feat. If you search for a name in a large AML screening database, you’ll probably find the person you’re looking for. What sets Xapien apart is our ability to match structured records from a database with the unstructured context around those records. That might be news articles, company websites, Wikileaks, and more.
Understanding structured vs unstructured data
Structured data refers to well-organised and easily searchable information stored in a predefined format, like spreadsheets or databases. Examples include financial records and customer relationship management data.
Unstructured data lacks a fixed structure and is often text-heavy. It’s normally found in documents, social media posts, and multimedia files. Unstructured data is too time-consuming for a human to analyse, but holds valuable insights.
How we approach disambiguation at Xapien
We’ve used large datasets of similar names, translated names, male and female names, and more to train our disambiguation engine. Our technology models every piece of information as ‘possibly’ true, capturing where it came from and our confidence in it.
Then, machine learning algorithms working on top of complex networks of probabilistic modelling determine which mentions are most likely to be relevant. We do this by modelling discovered information in a Knowledge Graph made up of entities and relationships.
These links and connections are gathered from structured data, such as sanctions databases, as well as text sources like news articles. Here are the key elements you need to know…
The knowledge graph
All identified entities are represented as nodes in a graph structure. Individuals, organisations, and other distinguishing features are nodes in this graph. Relationships are modelled as edges that connect the nodes.
Each mention or reference to an entity, such as the name ‘John’ in the sentence ‘John left the company,’ is represented as a node in the knowledge graph.
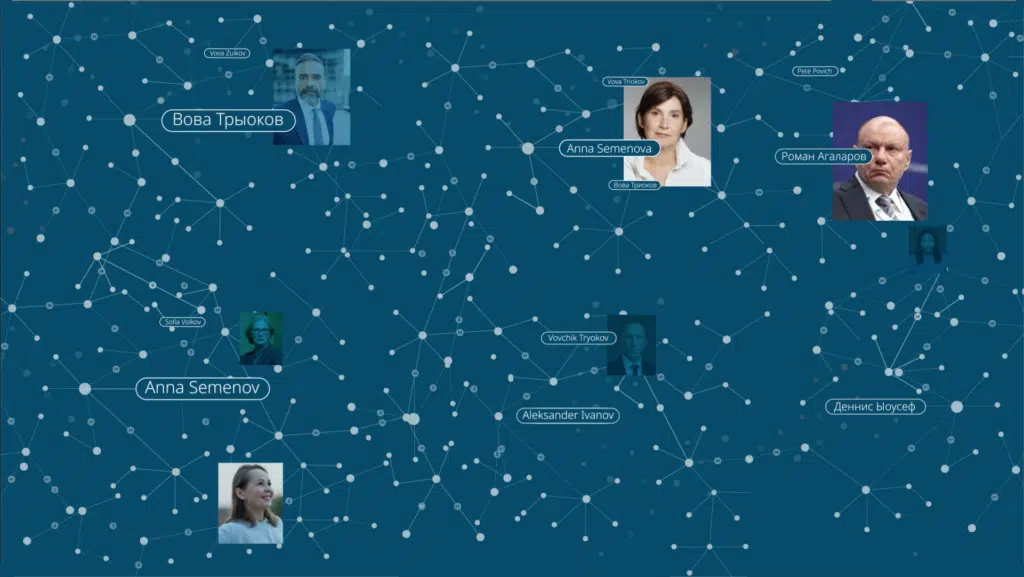
The knowledge graph allows us to carry out the following disambiguation tasks:
Name matching
Our disambiguation algorithm identifies name matches for the subject entity and all other entities. The strength of the match is taken into account every time.
Contextual connections
Our algorithm identifies contextual connections between specific references. It uses nearby information to assess the likelihood of two references referring to the same entity.
Consider the references ‘Max met with Roman Abramovich’ and ‘Roman Abramovich’s associate Max’. In this case, it’s highly likely that both references are referring to the same entity, namely ‘Max.’
However, if we take the reference ‘Max went to the shop’, it’s less likely to be referring to the same Max, unless there’s additional information that establishes a clear link between these two references.
Contradictory information
The algorithm identifies contradictory information that suggests two references cannot possibly refer to the same entity, like date of birth, middle name, or more complicated things like conflicting professional history.
Final steps
Once these key factors are established, our entity resolution process kicks in. It transforms the entity reference graph into a resolved graph. In this graph, each real-world entity is represented by a single node.
What’s next?
We’re constantly innovating at Xapien. The next version of our disambiguation engine will feature even more complicated, nuanced reasoning to push the accuracy to new levels and save users even more time. And, we aim to improve the explainability built into the system to better communicate why we have made certain entity resolution decisions.
Harness AI today
To discover more about how Xapien can boost efficiency and depth of insight at your organisation, book a demo today.
-crop")
Monthly learnings and insights to your inbox
Xapien streamlines due diligence
Xapien's AI-powered research and due diligence tool goes faster than manual research and beyond traditional database checks. Fill in the form to the right to book in a 30 minute live demonstration.